In this article we will describe what is the role of Apache Hadoop in IoT. First we will see an introduction to Apache Hadoop followed by Hadoop architecture and then HDFS.
Disclaimer: The content in this article was copied from the content available on intellipaat.com. The sole purpose of doing this is to make it easily available for students who are studying IoT in their curriculum.
Contents
Introduction
Apache Hadoop was born to enhance the usage and solve major issues of big data. The web media was generating loads of information on a daily basis, and it was becoming very difficult to manage the data of around one billion pages of content. In order of revolutionary, Google invented a new methodology of processing data popularly known as MapReduce.
Later after a year Google published a white paper of Map Reducing framework where Doug Cutting and Mike Cafarella, inspired by the white paper and thus created Hadoop to apply these concepts to an open-source software framework which supported the Nutch search engine project. Considering the original case study, Hadoop was designed with a much simpler storage infrastructure facilities.
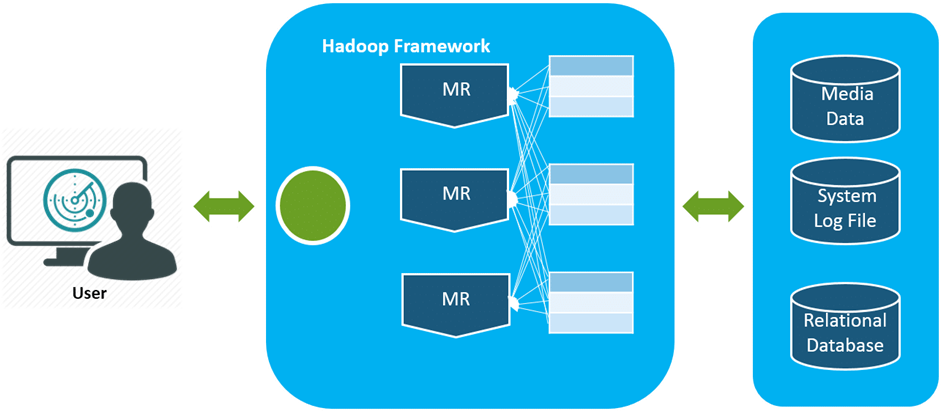
Apache Hadoop is the most important framework for working with Big Data. Hadoop biggest strength is scalability. It upgrades from working on a single node to thousands of nodes without any issue in a seamless manner.
The different domains of Big Data means we are able to manage the data’s are from videos, text medium, transactional data, sensor information, statistical data, social media conversations, search engine queries, ecommerce data, financial information, weather data, news updates, forum discussions, executive reports, and so on.
Hadoop is a framework which is based on java programming. It is intended to work upon from a single server to thousands of machines each offering local computation and storage. It supports the large collection of data set in a distributed computing environment.
Hadoop Architecture
Hadoop follows a master–slave architecture for storing data and data processing. This master–slave architecture has master nodes and slave nodes as shown in the image below:
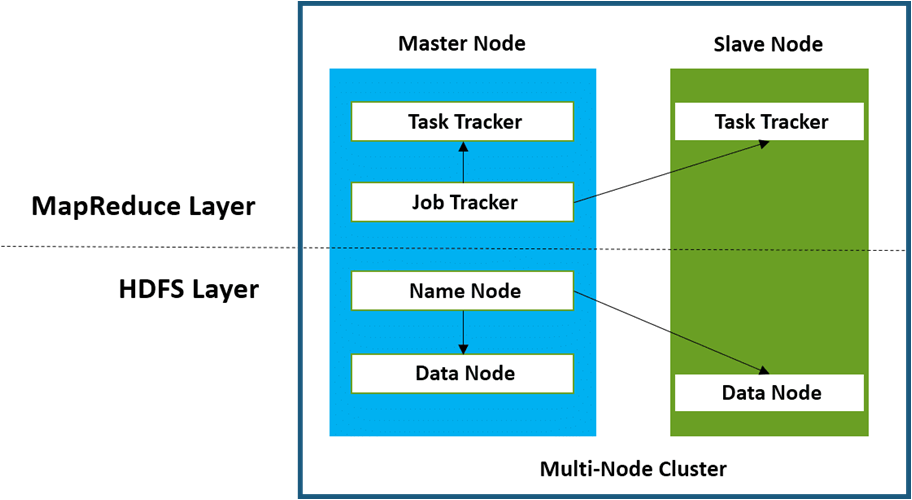
Let’s first look at each terminology before we start with understanding the architecture:
- NameNode: NameNode is basically a master node that acts like a monitor and supervises operations performed by DataNodes.
- Secondary NameNode: A Secondary NameNode plays a vital role in case if there is some technical issue in the NameNode.
- DataNode: DataNode is the slave node that stores all files and processes.
- Mapper: Mapper maps data or files in the DataNodes. It will go to every DataNode and run a particular set of codes or operations in order to get the work done.
- Reducer: While a Mapper runs a code, Reducer is required for getting the result from each Mapper.
- JobTracker: JobTracker is a master node used for getting the location of a file in different DataNodes. It is a very important service in Hadoop as if it goes down, all the running jobs will get halted.
- TaskTracker: TaskTracker is a reference for the JobTracker present in the DataNodes. It accepts different tasks, such as map, reduce, and shuffle operations, from the JobTracker. It is a key player performing the main MapReduce functions.
- Block: Block is a small unit wherein the files are split. It has a default size of 64 MB and can be increased as needed.
- Cluster: Cluster is a set of machines such as DataNodes, NameNodes, Secondary NameNodes, etc.
There are two layers in the Hadoop architecture. First, we will see how data is stored in Hadoop and then we will move on to how it is processed. While talking about the storage of files in Hadoop, HDFS comes to place.
Hadoop Distributed File System (HDFS)
HDFS is based on Google File System (GFS) that provides a distributed system particularly designed to run on commodity hardware. The file system has several similarities with the existing distributed file systems. However, HDFS does stand out among all of them. This is because it is fault-tolerant and is specifically designed for deploying on low-cost hardware.
HDFS is mainly responsible for taking care of the storage parts of Hadoop applications. So, if you have a 100 MB file that needs to be stored in the file system, then in HDFS, this file will be split into chunks, called blocks. The default size of each block in Hadoop 1 is 64 MB, on the other hand in Hadoop 2 it is 128 MB.
For example, in Hadoop version 1, if we have a 100 MB file, it will be divided into 64 MB stored in one block and 36 MB in another block. Also, each block is given a unique name, i.e., blk_n (n = any number). Each block is uploaded to one DataNode in the cluster. On each of the machines or clusters, there is something called as a daemon or a piece of software that runs in the background.
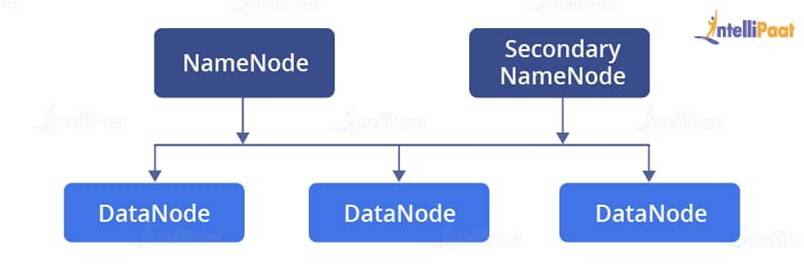
The daemons of HDFS are as follows:
- NameNode: It is the master node that maintains or manages all data. It points to DataNodes and retrieves data from them. The file system data is stored on a NameNode.
- Secondary NameNode: It is the master node and is responsible for keeping the checkpoints of the file system metadata that is present on the NameNode.
- DataNode: DataNodes have the application data that is stored on the servers. It is the slave node that basically has all the data of the files in the form of blocks.
HDFS stores the application data and the files individually on dedicated servers. The file content is replicated by HDFS on various DataNodes based on the replication factor to assure the authenticity of the data. The DataNode and the NameNode communicate with each other using TCP protocols.
MapReduce Layer
MapReduce is a patented software framework introduced by Google to support distributed computing on large datasets on clusters of computers. It is basically an operative programming model that runs in the Hadoop background providing simplicity, scalability, recovery, and speed, including easy solutions for data processing. This MapReduce framework is proficient in processing a tremendous amount of data parallelly on large clusters of computational nodes.
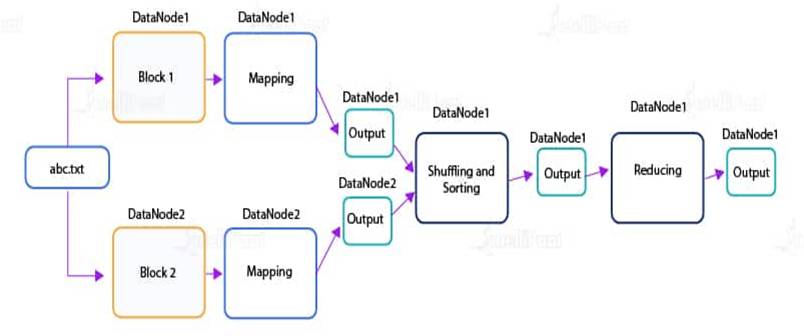
MapReduce is a programming model that allows you to process your data across an entire cluster. It basically consists of Mappers and Reducers that are different scripts you write or different functions you might use when writing a MapReduce program.
Mappers have the ability to transform your data in parallel across your computing cluster in a very efficient manner; whereas, Reducers are responsible for aggregating your data together. Mappers and Reducers put together can be used to solve complex problems.

Suryateja Pericherla, at present is a Research Scholar (full-time Ph.D.) in the Dept. of Computer Science & Systems Engineering at Andhra University, Visakhapatnam. Previously worked as an Associate Professor in the Dept. of CSE at Vishnu Institute of Technology, India.
He has 11+ years of teaching experience and is an individual researcher whose research interests are Cloud Computing, Internet of Things, Computer Security, Network Security and Blockchain.
He is a member of professional societies like IEEE, ACM, CSI and ISCA. He published several research papers which are indexed by SCIE, WoS, Scopus, Springer and others.
Leave a Reply