In this article we will look at Hypertext Transfer Protocol (HTTP), one of the widely used application layer protocols in IoT.
Contents
What is HTTP?
HTTP stands for Hypertext Transfer Protocol. It was developed by Tim Berners-Lee at CERN (Switzerland) alongside other concepts that laid the basis for the world wide web, such as HTML and URI. While HTML (Hypertext Markup Language) defines the structure and layout of a website, HTTP controls how the page is transferred from the server to the client. If you enter an internet address in your web browser and a website is displayed shortly thereafter, your browser has communicated with the web server via HTTP.
The easiest way to explain how HTTP works is by looking at an example of how a website is requested as shown in figure below.
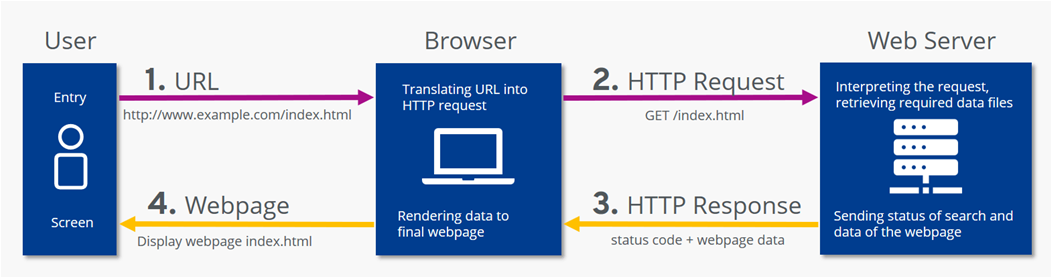
- The user types example.com into the address bar of their internet browser.
- The browser sends the respective request (i.e. the HTTP Request) to the web server that manages the domain example.com.
- The web server receives the HTTP request, searches for the desired file (in this example, the homepage example.com, meaning the file index.html), and begins by sending back the header which informs the requesting client of the search result with a status code.
- If the file was found and the client wants it to be sent (and did not just wish to know whether it existed), the server sends the message body after the header (i.e. the actual content). In our example, this is the file index.html.
- The browser receives the file and displays it as a website.
When is HTTP used?
Originally, HTTP was only used to request an HTML document from a web server. Today, the protocol has many different uses:
- Browsers use HTTP to request all types of media used on modern websites: text, images, videos, program code, etc.
- Application programs use HTTP to request files and updates from remote servers.
- The REST-API is an HTTP-based solution for handling web services.
- HTTP is used in machine-to-machine communication as a protocol for communicating between web services.
- Media players also use HTTP.
- Databases on the web can also be accessed (i.e. CRUD operations) using HTTP.
HTTP Versions
HTTP/1
The history of HTTP began in 1989 when Tim Berners-Lee and his team at CERN developed the world wide web. The original version of HTTP was labelled version 0.9 and called the “One-Line Protocol”. It could only request one HTML file from a server. All the server did was send the corresponding file. Therefore, this protocol version could only handle HTML files.
In 1996, the Internet Engineering Task Force (IETF) documented version HTTP/1 in the non-binding informational memo RFC 1945. A new header was introduced which could specify both the client request and the server response more precisely. One new header introduced was the “content type” header which made it possible to transfer files other than HTML files. The following is a short summary of this HTTP version’s features: Connectionless, Stateless, Media-independent. The following is a short summary of this HTTP version’s features: Connectionless, Stateless, Media-independent.
HTTP/1.1
In 1997, version HTTP/1.1 was published, as documented in the informational memo RFC 2068. It became the first official standard and is still being used today. It offered some important innovations in comparison to HTTP/1:
- Keepalive: The client can keep a connection from a request open (i.e. a persistent connection) by sending a keepalive in the header of the request.
- HTTP pipelining allows the client to send another request before it has received a response to the first one.
- In chats the browser can update the browser window using the MIME type multipart/replace.
- Data can also be sent from the client to the server.
- The newly introduced TRACE method allows you to trace the path from the client to the web server.
- Cache: There are new mechanisms for caching content.
- Host: An HTTP request will work due to a given specification in the header (i.e. host) even if several different domains are hosted under a single IP address, as is the case with the majority of websites today (i.e. shared webhosting).
HTTP/2
Over the years, websites have become larger and more complex. To load a modern website in your browser, the browser will need to request several megabytes of data and send up to several hundred HTTP requests. Since HTTP/1.1 requires requests over a connection to be processed one after the other, the more complex the website is, the longer it will take to load the page. In response, Google developed a new experimental protocol called SPDY (pronounced “speedy”). This was met with great interest by the developer community and finally led to the release of the protocol version HTTP/2 in 2015.
This new standard introduced the following non-comprehensive list of innovations, all of which are intended to speed up the loading time of websites:
- Binary: The protocol is based on binary data instead of text files.
- Multiplexing: The client and server can send or process several HTTP requests at the same time.
- Compression: The headers are compressed. Since headers are often almost identical in many HTTP requests, compressing them eliminates unnecessary redundancy.
- Server push: If the server already knows what data the client will require, it can send it to a client cache by itself without having received a previous HTTP request.
HTTP/3
A weak point of all the previous HTTP versions has been the underlying transport protocol TCP. This protocol requires the recipient to confirm each data packet before the next one can be sent. If a single data packet is lost, all the other packets have to wait for the lost one to be sent again. Experts refer to this as head-of-line blocking.
The new HTTP/3 will, therefore, no longer be based on TCP but rather on UDP which does not require any corrective measures for this kind of situation. The QUIC protocol (Quick UDP Internet Connections) was developed based on UDP as the foundation for HTTP/3. HTTP/3 has not yet been definitively adopted by the IETF. Nevertheless, almost 3% of websites already use QUIC or HTTP/3 according to W3Techs.
HTTP Request Types
The HTTP protocol has different HTTP methods like:
- GET
- POST
- HEAD
- TRACE
- Other Specialized methods
HTTP Header
When you visit a website, your browser sends a request to the web server to obtain data or information from it, e.g. an HTML file (i.e. a web page). Both in the request – the HTTP-Request – and in the server’s response, some meta-information is exchanged in addition to the actual data. This is summarized in the HTTP header. When the website www.example.com is opened, the web server not only opens the website itself, but also sends out – invisible to users – the following header:
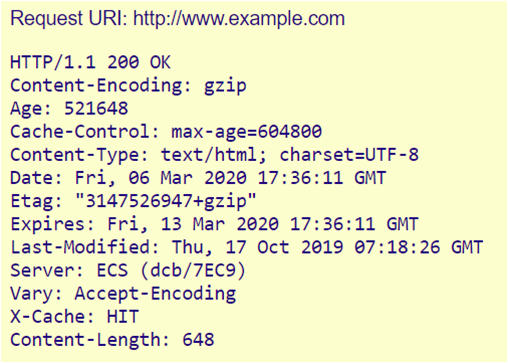
The individual lines are called “header fields”. Each (except the first) consists of a name/value pair separated by a colon. The fields in the above header are:
- HTTP/1.1 is the valid HTTP protocol version
- 200 OK is the Status-Code. It says that the server has received, understood and accepted the request
- Content-Encoding and Content-Type tell us about the type of file
- Age, Cache-Control, Expires, Vary and X-Cache refer to the caching of the file
- Etag and Last-Modified are used for version control of the delivered file
- Server refers to the web server software
- Content-Length is the file size in bytes
HTTPS
HTTPS (“hypertext transport protocol secure”) is the protocol used for secure data transfer, whereas HTTP refers to the non-secured variant. With HTTP websites, all transferred data can potentially be read or changed by attackers, and users can never really be certain whether their credit card data has been sent to the intended online vendor or a hacker.
HTTPS encrypts data and verifies the authenticity of requests. This process takes place via the SSL certificate or the more sophisticated TLS certificate. The advantages of using SSL/TLS and HTTPS are:
- Data protection and security for customers and partners
- Minimized risk of data theft and abuse of personal information
- Positive ranking factor on Google
- Enables use of HTTP/2 for improved website performance
- Certificates are easy for users to recognize and help to build trust

Suryateja Pericherla, at present is a Research Scholar (full-time Ph.D.) in the Dept. of Computer Science & Systems Engineering at Andhra University, Visakhapatnam. Previously worked as an Associate Professor in the Dept. of CSE at Vishnu Institute of Technology, India.
He has 11+ years of teaching experience and is an individual researcher whose research interests are Cloud Computing, Internet of Things, Computer Security, Network Security and Blockchain.
He is a member of professional societies like IEEE, ACM, CSI and ISCA. He published several research papers which are indexed by SCIE, WoS, Scopus, Springer and others.
Leave a Reply